This feature a paid add on that can be added to your plan. If you are interested in turning it on for your academy please let us know at support@vedamo.com and we will contact you back as soon as possible.
The Transcripts Settings allow you to record all spoken words during online sessions, complete with precise timestamps and the option to add Keyword Alerts. This option will allow you to monitor the in-class activity and what language is used in the sessions.
To turn on the option for transcription go to the Account and Settings menu and select the General Settings option. From there navigate to the LMS section where you will be able to find the option.
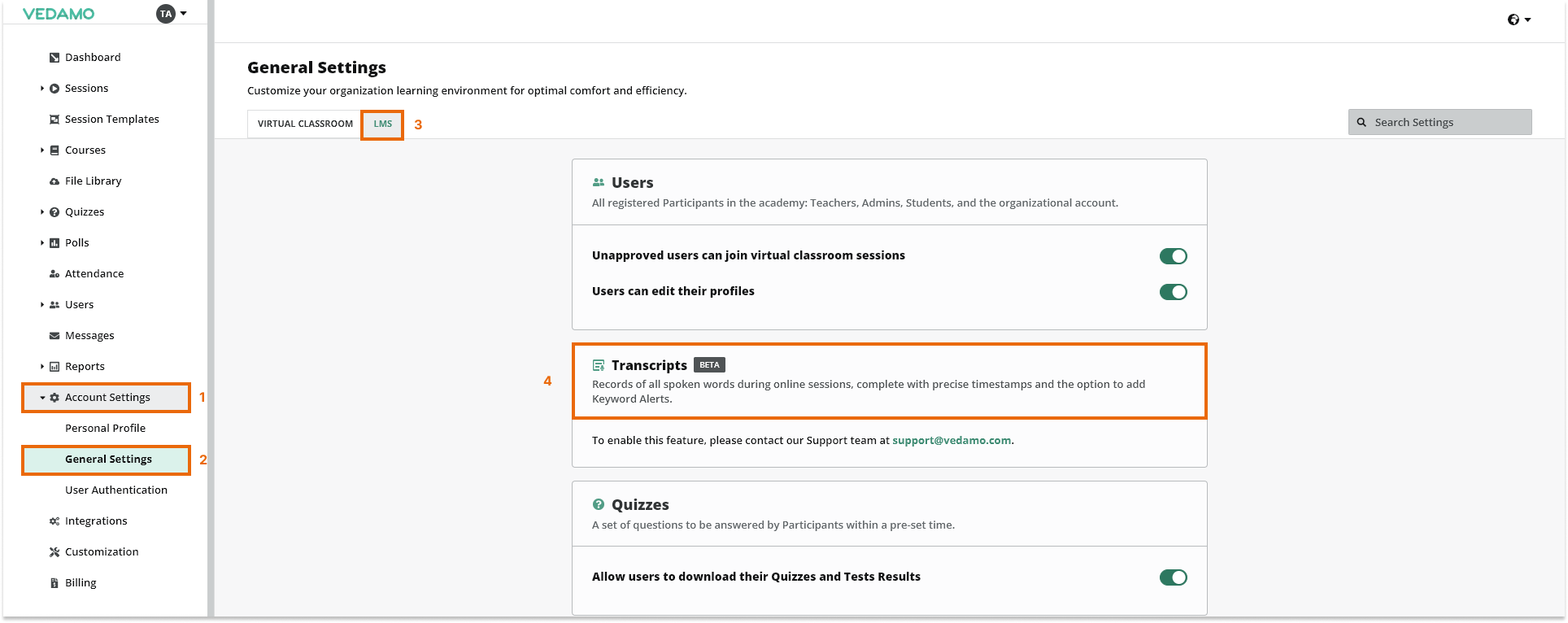
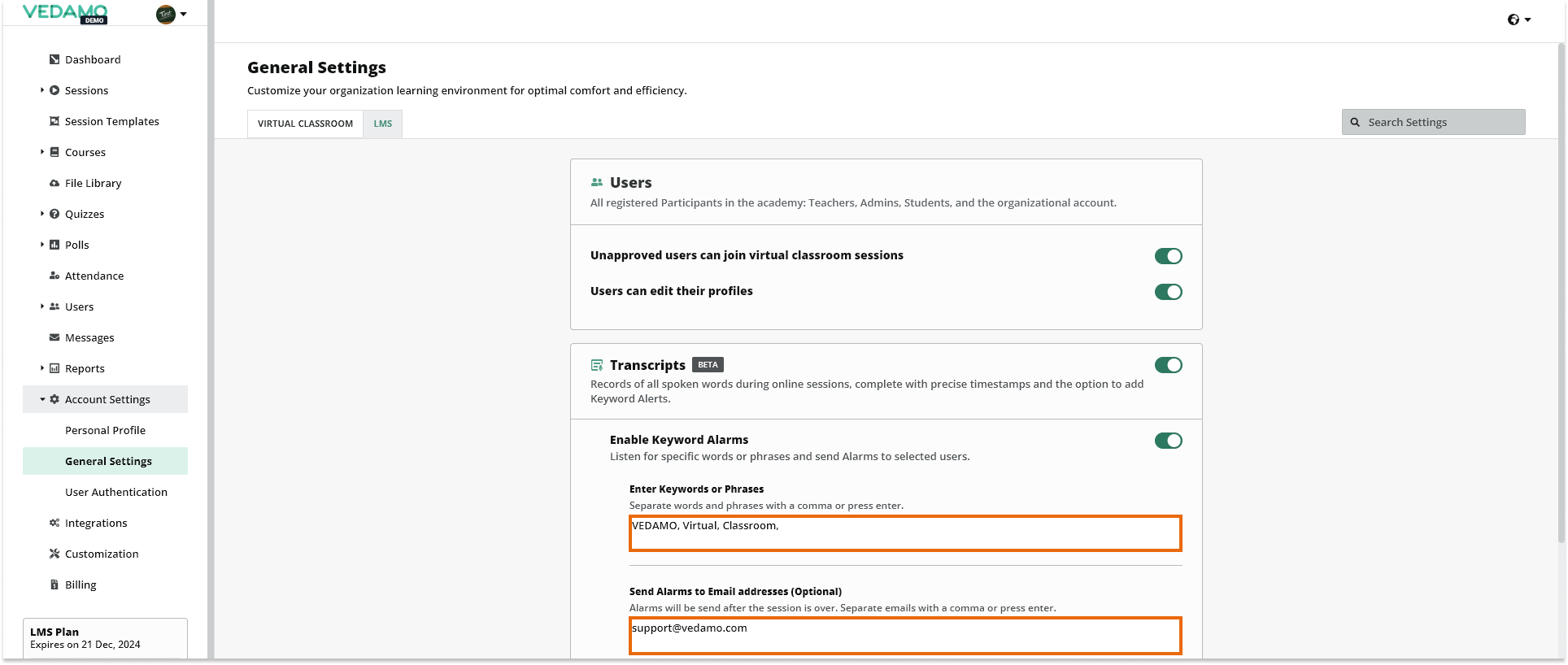
To select the keywords you want enter them here separated with a comma or each word/keyphrase on a new row.
There is also an option to send notifications via email for each time that a keyword has been used. To enable that put in the email address that you want to receive those notifications here:
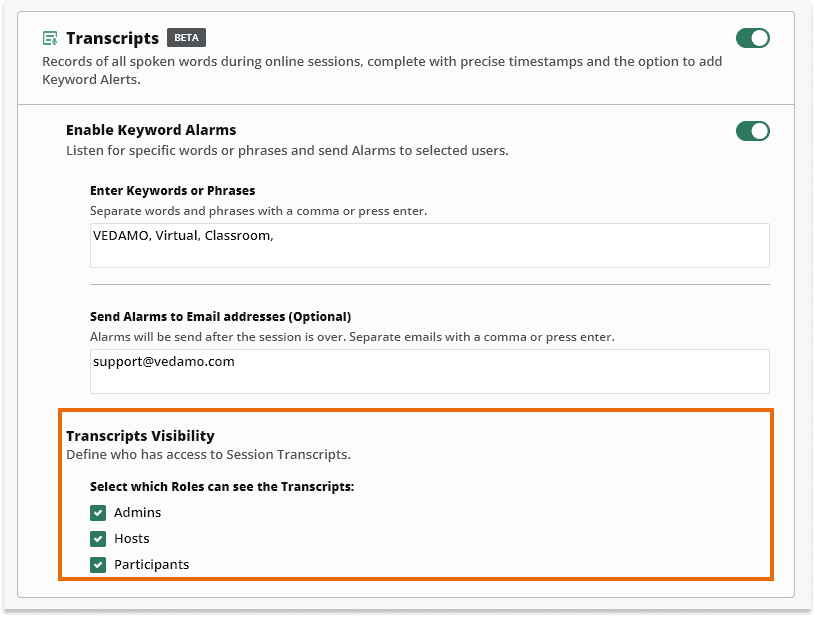
You can also select the roles that you want to have access to the transcripts – for example you can select only admins to have access to this option, or everyone:
The transcripts settings will be available for recurring events as well. You can find the details of the transcripts in the recurring event details:
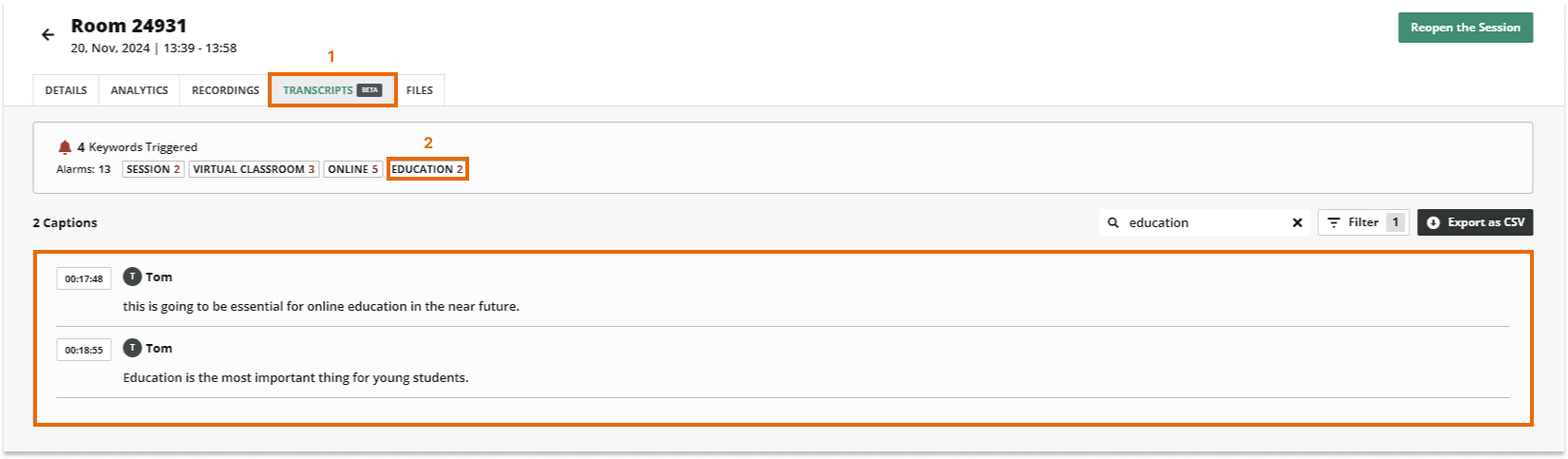
You can search by keyword or phrase, filter or export to csv:
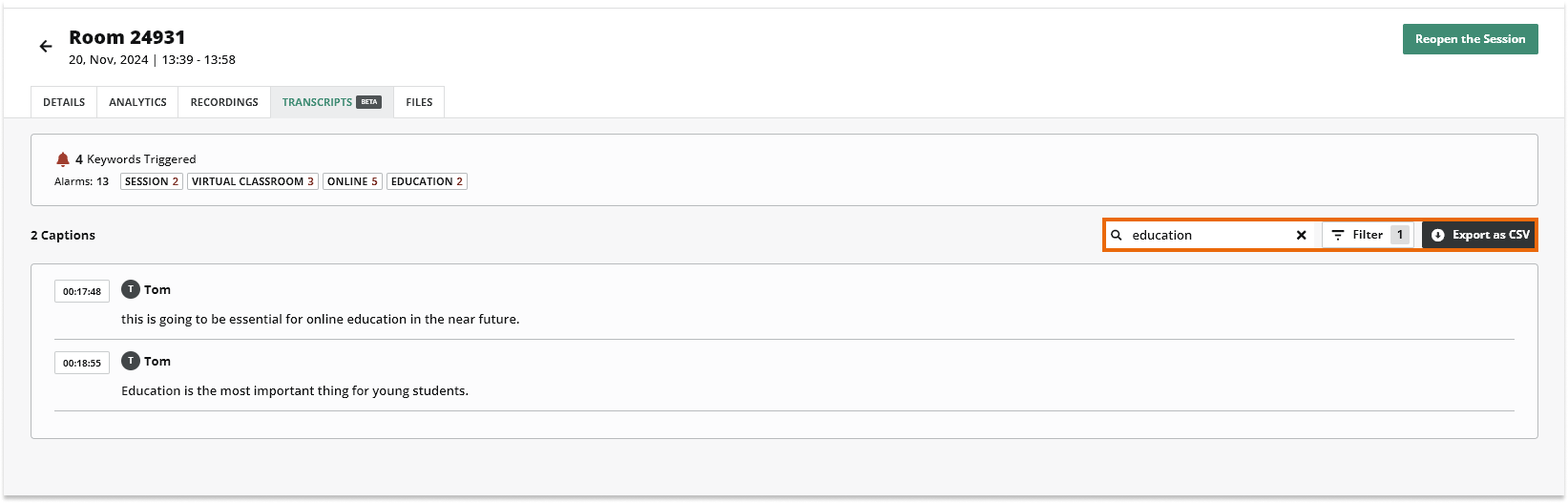
The Export to csv option sends you an email with all of the results.
The supported languages are Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
While the underlying model was trained on 98 languages, we only list the languages that exceeded <50% word error rate (WER) which is an industry standard benchmark for speech to text model accuracy. The model will return results for languages not listed above but the quality will be low.